웹 크롤링 이란,
컴퓨터 소프트웨어 기술로 웹 사이트들에서 원하는 정보를 추출하는 것을 의미합니다
웹 크롤러 란,
인터넷에 있는 웹페이지를 방문해서 자료를 수집하는 일을 하는 프로그램을 말합니다
여러 웹 크롤러가 존재합니다
저는 그중 Jsoup을 사용해 보도록 하겠습니다
Jsoup은 HTML 파싱 Java 라이브러리입니다
주로 정적인 웹 페이지를 파싱하고자 하는 경우,
간단하게 HTML을 가져와 파싱을 할 수 있는 라이브러리입니다.
간단하게 말하면 화면을 만들기 위해 사용되는 html태그 및 정보들을 가져와
새로운 구조를 만든다고 생각하면 됩니다
외부의 라이브러리에서 사용하기에,
라이브러리에 등록하고 connect를 해주어야 사용 가능합니다
final String url = "https://comic.naver.com/webtoon/weekdayList?week=mon";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Elements eles = doc.select("#content > div.list_area.daily_img > ul > li:nth-child(1) > dl > dt > a");
Iterator<Element> itr = eles.iterator();
while(itr.hasNext()) {
String name = itr.next().text();
System.out.println(name);
}
1. URL (주소)을 설정해주어야한다
final String url = "https://comic.naver.com/webtoon/weekdayList?week=mon";- 어디의 URL정보를 사용할지 알기 위해서
String 변수에 담아 편하게 사용합니다
2. Document 설정
Document doc = null;- JAVA에서 제공하는 것이 아닌 Jsoup에서 제공하는 클래스입니다
- URL의 HTML 코드를 담아주기 위한 클래스 입니다
-변수로 사용하기 위해 미리 null로 초기화 시켜 놓았습니다
3. doc = Jsoup.connect(URL).get();
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}- Jsoup은 외부 라이브러리이기때문에 connect 해줘야 합니다
- 인풋값의 URL안에있는 HTML코드를 get(); 으로 불러주는데
아웃풋이 Document 이기에 doc 변수에 담아서 사용합니다
- URL값이 잘못됐는지 안됐는지 확인하기 어렵기 때문에 try/catch 강제입니다
- doc를 출력해 보았을때의 콘솔창 입니다
( HTML의 코드를 보여줍니다. 네이버 월요웹툰 URL 입니다 )
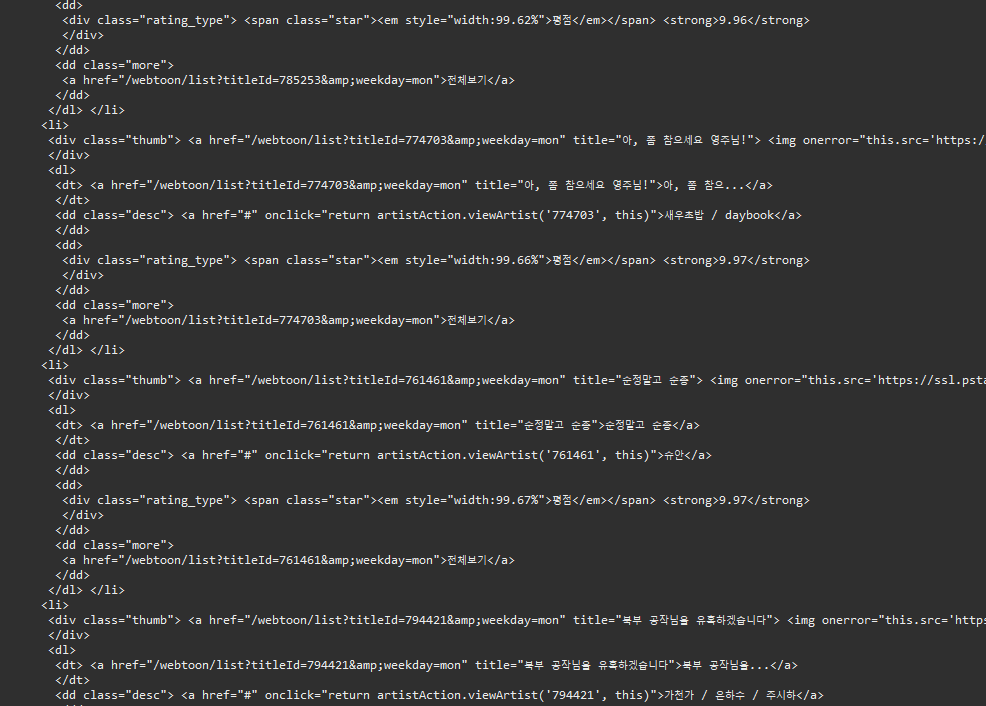
HTML에서 원하는 값 가져오는 방법 **
4. Elements else = doc.select( " 태그명, class속성명, id 속성명 " );
Elements eles = doc.select("#content > div.list_area.daily_img > ul > li:nth-child(1) > dl > dt > a");- select로 불러온 값들을 저장할 Elements 클래스입니다
해당 클래스는 Jsoup의 클래스입니다
Elements = 배열을 구성하는 각각의 값을 배열 요소(element) 라고 합니다
그 중 요소라는 뜻을 가졌습니다
HTML에서 원하는 값을 가져오는 기본적인 방법
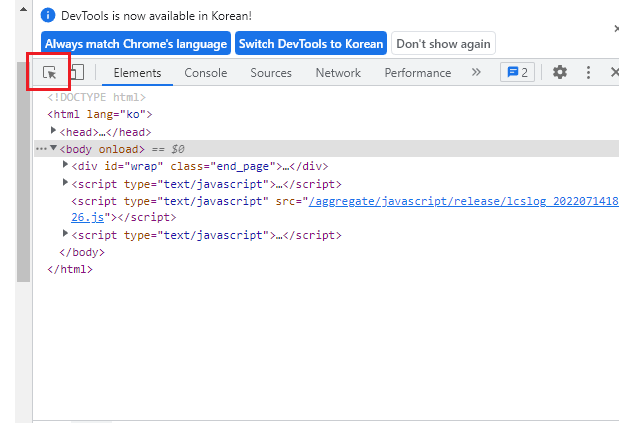
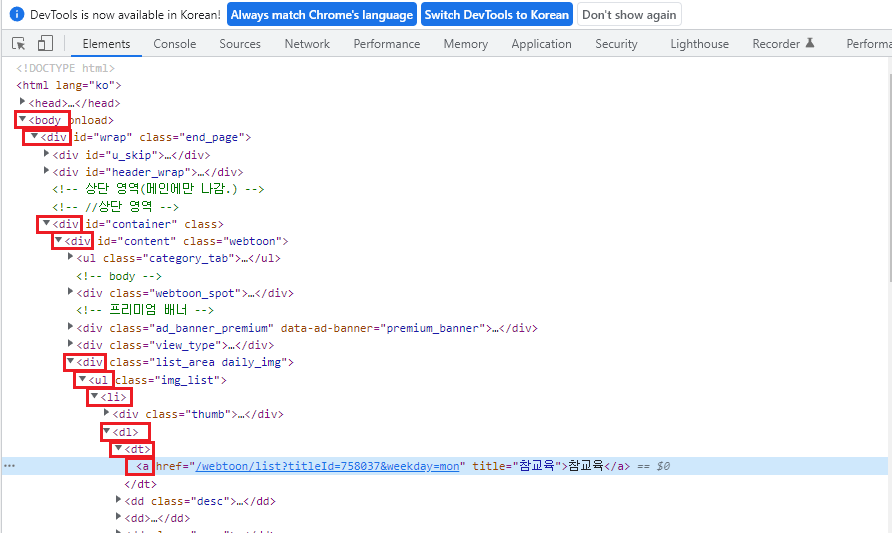
현재 URL에서 F12를 누르면 해당 창이 나오는데,
네모 박스를 클릭하여필요한 정보에 마우스를 올려 클릭하면,
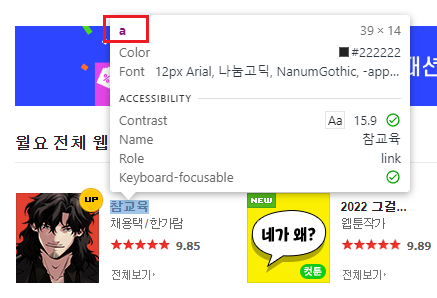
해당 '태그' 의 정보를 알려주며 (네모박스)
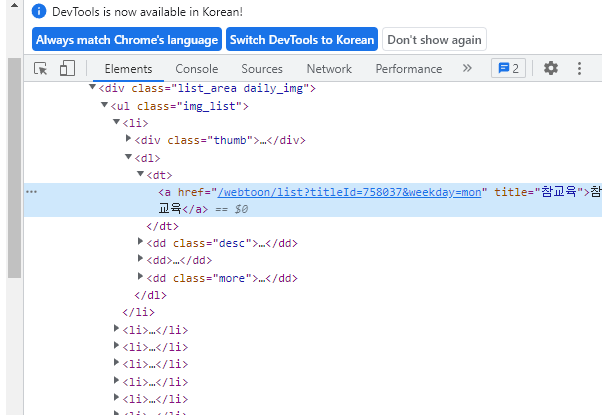
어디에 있는지 알려줍니다!
doc.select( 인풋값 )으로 경로를 보내주면 되는데
" 참교육 " 이라는 정보를 가져와 보도록 하겠습니다
body > div > div > div > div > ul > li > dl > dt > a
~태그 안에 > ~태그 안에 > ~태그 안에 라는 생각으로 들어갑니다
해당 방법으로는 <dt> class 에 포함된 모든 <a>를 불러옵니다
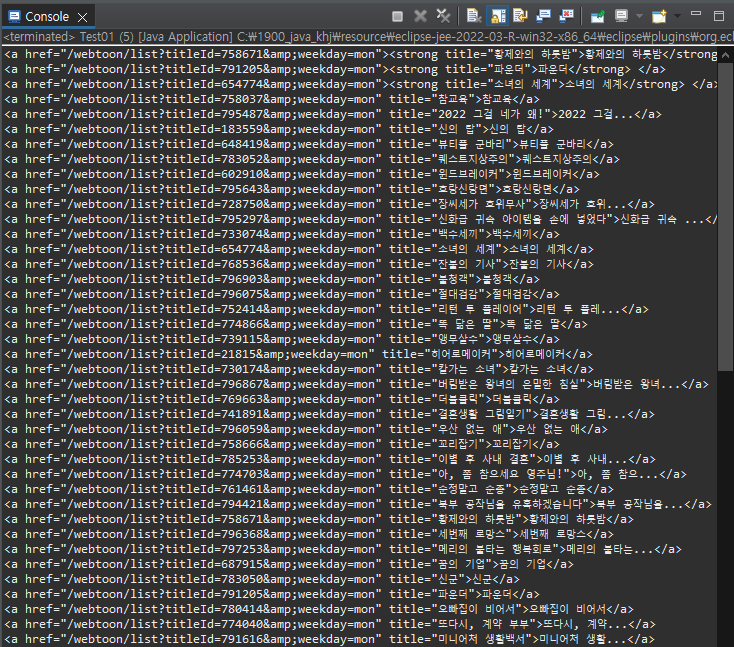
Elements else = doc.select(body>div>div>div>div>ul>li>dl>dt>a)
else를 출력 했을때의 콘솔창입니다
참교육이라는 값 하나만을 부르고 싶다면
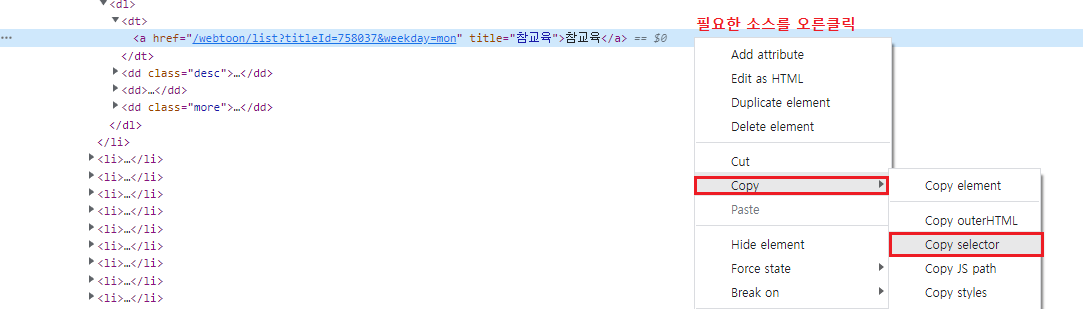
복사한 것을 doc.select( 안에 넣어준다면 )

해당 요소만 뽑아올 수 있다
복사한 값의 결과값이 2가지 종류로 나뉘는데
1. li:nth-child( 정수 ) - 공식을 가진 코드
- 이런식으로 어떠한 곳에 정수가 있다면, 해당 정수를 변경해주면
그 정수의 위치에 있는 값을 가져온다
- li 만 남기고 다 지운다면
정수값으로 들어가는 모든 경우를 가져와 준다는 것을 생각해 볼 수 있다
(사용해보면 익숙해 질 것이다)
2. 공식이 없는 코드

- 이땐 태그뒤에 붙은 . 을 기준으로 HTML을 보며 비교해본다
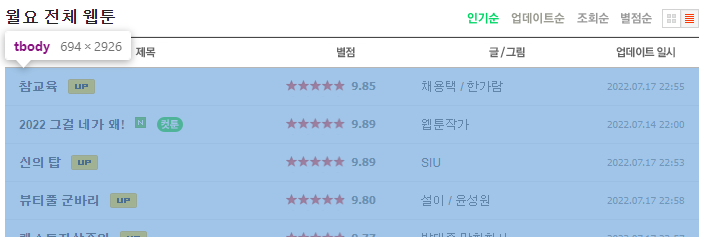

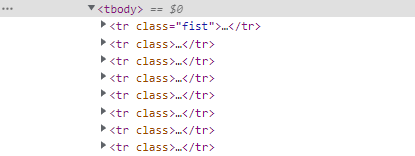
tr.fist 부분을 접어보니, 웹툰 제목의 값들이
tr클래스안에 하나씩 저장되어있는 것을 확인
.fist를 지워 모든 tr 클래스를 불러온다면
해당 웹툰페이지의 제목을 모두 가져올 수 있다고 예상가능하다
( .fist를 지운후 출력해본 콘솔창 )
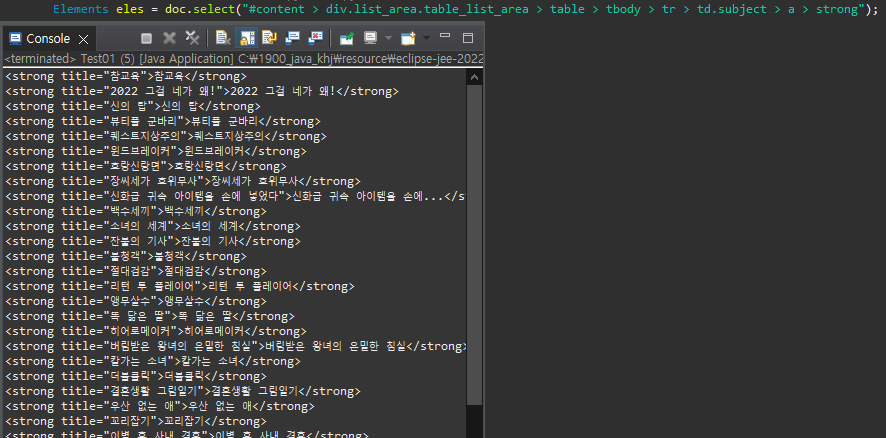
5. Elements 들을 배열 Iterator에 저장
Iterator<Element> itr = eles.iterator();- eles.iterator();
Iterator에 저장하여 사용하기위해 만들어진 Elements의 메소드이며,
해당 메소드도 Jsoup에서 iterator를 사용하기 위한 메소드 입니다
6. lterator를 사용
while(itr.hasNext()) {
String name = itr.next().text();
System.out.println(name);
}itr.hasNext()
- 다음 값이 존재하니? T or F
itr.next()
- 배열에 차례로 저장된 하나의 값을 가져옴
- 아웃풋이 Elements 이다
.txet()
- Elements의 메소드이며,
태그값을 제외한 원하는 값만을 가져온다+ String 값으로 바꿔준다
해당 String name값을 이용하면
CRUD를 이용하여 데이터베이스에 사용할 수 있을 것이다!
doc.select( ) 메서드 말고도
doc.doc.getElementsByClass( ) 클래스만 찾는 전용 메서드
등등 여러가지가 있으니 추가 공부 할 것
'자바(JAVA)' 카테고리의 다른 글
| (18)Model View Controller (MVC) (0) | 2022.06.28 |
|---|---|
| (17) throw 와 throws 의 차이 (0) | 2022.06.28 |
| (16) 파일 입출력 (0) | 2022.06.27 |
| (15) 콜론 ( : ) 의 기능 (0) | 2022.06.27 |
| (14) Exception(try,catch,throw) (0) | 2022.06.24 |